로지스틱 회귀와 분류 모델의 성능 평가 지표는 분류 문제에서 중요한 개념들로, 각각을 이해하는 것이 모델의 해석과 성능 개선을 할 수 있다.
1. 로지스틱 회귀(Logistic Regression)
로지스틱 회귀는 회귀 분석과는 달리, 종속 변수가 범주형(이산적 값, 예: 0 또는 1)일 때 사용된다. 예를 들어, 이메일이 스팸인지 아닌지(스팸: 1, 정상: 0)와 같은 2진 분류에서 유용하다. 로지스틱 회귀는 독립 변수들의 선형 결합을 사용해 분류 결정의 기준을 확률로 변환하고, 이 확률을 사용해 특정 클래스에 속하는지 여부를 판단한다.
모델 구조: 로지스틱 회귀는 선형 회귀에서 도출된 값을 확률로 변환하는 과정을 포함한다. 다음은 로지스틱 회귀의 예측 확률 수식이다.
$P(y=1 \mid X)=\frac{1}{1+e^{-z}}$,
여기서 z는 회귀식 z=β0+β1X1+β2X2+⋯+βnXn이며, 시그모이드 함수에 의해 이 값은 0에서 1 사이의 확률로 변환된다.
여기서 X1,X2,…,Xn은 독립 변수들이고 β0,β1,…,βn은 각 독립 변수에 대한 가중치(회귀 계수)다.
선형 회귀 모델에서는 $z$가 어떤 값이든 출력될 수 있지만, 분류 문제에서는 이 값을 시그모이드 함수를 통해 확률로 변환해 0과 1 사이의 값으로 압축한다.
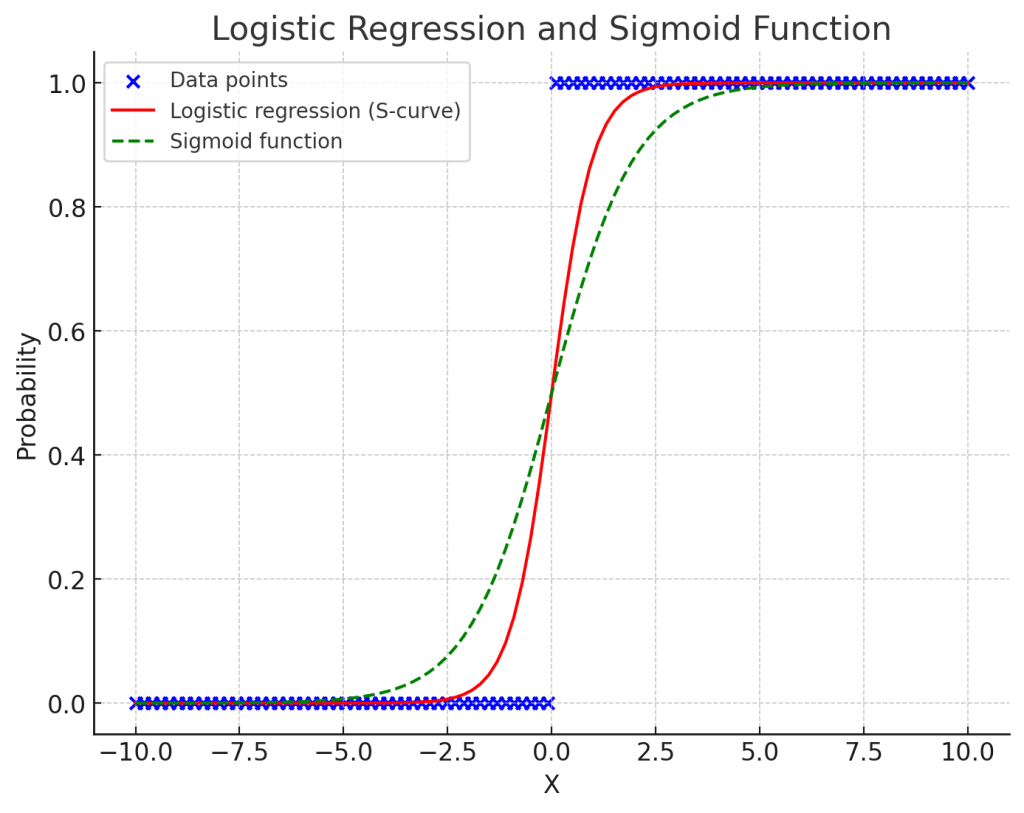
로지스틱 회귀는 분류 문제에 자주 사용되는 기법으로, 결과가 두 가지 범주 중 하나로 나뉠 때 사용된다. 로지스틱 회귀는 데이터의 추세를 S자 형태의 곡선(시그모이드 함수)으로 나타낸다.
위 그래프에서 파란 점들은 이진 데이터 포인트를 나타내며, 빨간 선은 로지스틱 회귀 모델에서 예측된 확률을 나타내는 S자 곡선이다. 초록색 점선은 수학적 시그모이드 함수를 나타낸다
2. 시그모이드 함수(Sigmoid Function)
시그모이드 함수는 로지스틱 회귀에서 매우 중요한 역할을 하며, 선형 회귀에서 도출된 값을 0과 1 사이의 값으로 변환한다. 이 변환된 값은 분류 문제에서 해당 데이터 포인트가 특정 클래스(예: 클래스 1)에 속할 확률로 해석된다.
- 시그모이드 함수의 수식
$\sigma(z)=\frac{1}{1+e^{-z}}$
여기서 ( e )는 자연 로그의 밑(약 2.718)이며, ( z )는 선형 회귀에서 도출된 값이다. 시그모이드 함수의 결과는 확률로 해석되므로, 일반적으로 0.5를 기준으로 예측한다.
- ( $\sigma(z) \geq 0.5$ )이면 클래스 1로 예측
- ( $\sigma(z) < 0.5$ )이면 클래스 0으로 예측
- 시그모이드 함수의 특성:
- ( $z \to \infty$ )일 때 ( $\sigma(z) \to 1$ ): 매우 큰 ( $z$ ) 값일 때 클래스 1일 확률이 높다.
- ( $z \to -\infty$ )일 때 ( $\sigma(z) \to 0$ ): 매우 작은 ( $z$ ) 값일 때 클래스 0일 확률이 높다.
- ( $z = 0$ )일 때 ( $\sigma(z) = 0.5$ ): 클래스 1과 0의 경계다.
3. 오차행렬(Confusion Matrix)
오차행렬은 모델의 성능을 직관적으로 확인할 수 있다. 특히 분류 모델에서 실제 클래스와 예측된 클래스 간의 관계를 파악하는 데 유용하다. 오차행렬은 다음과 같은 4가지 지표로 구성된다.
| 예측 클래스 0 | 예측 클래스 1 | |
|---|---|---|
| 실제 클래스 0 | True Negative (TN) | False Positive (FP) |
| 실제 클래스 1 | False Negative (FN) | True Positive (TP) |
- True Positive (TP): 실제로 클래스 1이고, 모델도 1로 예측한 경우
- True Negative (TN): 실제로 클래스 0이고, 모델도 0으로 예측한 경우
- False Positive (FP): 실제로 클래스 0인데, 모델이 잘못하여 1로 예측한 경우 (Type I 오류)
- False Negative (FN): 실제로 클래스 1인데, 모델이 잘못하여 0으로 예측한 경우 (Type II 오류)
오차행렬은 모델의 성능을 다양하게 분석할 수 있게 해주며, 이것으로 여러 성능 지표를 계산할 수 있다.
정확도(Accuracy)란
정확도(Accuracy)는 모델이 올바르게 예측한 비율을 의미한다. 즉, 전체 예측 중에서 얼마나 많은 예측이 정확했는지를 나타내는 지표다.
정확도는 다음과 같이 계산된다.
정확도(Accuracy) = $\frac{TP + TN}{TP + TN + FP + FN}$
예시
- TP: 40, TN: 30
- FP: 10, FN: 20
이 경우, 정확도는 다음과 같이 계산된다.
Accuracy = $\frac{40 + 30}{40 + 30 + 10 + 20} = \frac{70}{100} = 0.7 = 70\%$
4. 정밀도(Precision)
정밀도는 모델이 긍정 클래스로 예측한 데이터 중 실제로 긍정인 데이터의 비율을 의미한다. 즉, 모델이 예측한 것 중에서 얼마나 정확하게 맞췄는지를 나타낸다.
- 수식
Precision $=\frac{T P}{T P+F P}$
정밀도는 False Positive가 중요한 문제에서 고려된다. 예를 들어, 이메일 스팸 필터에서 정밀도가 높다면, 스팸으로 잘못 분류된 정상 이메일이 적다는 의미다.
- 적용 예시
- 스팸 필터링: 스팸으로 예측한 이메일 중 실제 스팸 비율이 높아야 한다.
- 암 진단: 암 양성으로 예측한 환자 중 실제로 암인 비율이 중요하다.
5. 재현율(Recall)
재현율은 실제로 긍정인 데이터 중 모델이 얼마나 긍정으로 잘 예측했는지를 나타내는 비율이다. 즉, 놓친 긍정 데이터를 얼마나 줄였는지에 대한 지표이다.
- 수식
Recall = $\frac{TP}{TP + FN}$
재현율은 False Negative가 중요한 문제에서 매우 중요한 지표이다. 예를 들어, 질병 진단에서는 재현율이 높아야 실제로 환자가 질병을 가지고 있는 경우를 놓치지 않게 된다.
- 적용 예시
- 암 진단: 실제 암 환자 중 진단에서 양성으로 판별된 환자 비율이 중요하다
- 범죄 예측: 실제 범죄가 발생할 때 이를 잘 예측하는 것이 중요하다.
6. F1 스코어(F1 Score)
정밀도와 재현율은 서로 상충하는 관계에 있을 수 있다. 한 지표가 높아지면 다른 지표가 낮아질 수 있기 때문에, 이를 균형 있게 평가할 수 있는 지표가 필요하다. F1 스코어는 정밀도와 재현율의 조화 평균으로, 두 지표 간의 균형을 평가할 수 있다.
- 수식
F1 = 2 $\times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}$
F1 스코어는 정밀도와 재현율이 균형을 이루도록 하며, 특히 데이터가 불균형할 때 유용한 지표다. F1 스코어가 높을수록 정밀도와 재현율이 모두 높다는 것을 의미한다.
- 적용 예시
- 의료 진단: 질병 진단에서 놓치지 않으면서도, 잘못된 양성 진단을 줄이기 위해 F1 스코어가 유용할 수 있다.
- 스팸 필터: 스팸을 잘 잡아내면서, 정상 메일을 스팸으로 분류하지 않기 위한 균형을 평가하는 데 F1 스코어가 중요하다.
7. ROC 곡선(Receiver Operating Characteristic Curve)
ROC 곡선은 모델의 성능을 시각적으로 평가하는 도구로, 다양한 임계값에서의 True Positive Rate(재현율)와 False Positive Rate의 변화를 나타낸다. 임계값을 다르게 설정하면서, 각 임계값에서 얼마나 잘 분류하는지를 평가할 수 있다.
- True Positive Rate (TPR):
TPR = $\frac{TP}{TP + FN}$ = 재현율(Recall)
실제 긍정인 데이터 중 긍정으로 정확히 분류한 비율이다.
- False Positive Rate (FPR):
FPR = $\frac{FP}{FP + TN}$
실제로는 부정인데 모델이 긍정으로 잘못 예측한 비율이다. 모델이 False Positive를 얼마나 많이 내는지를 나타낸다.
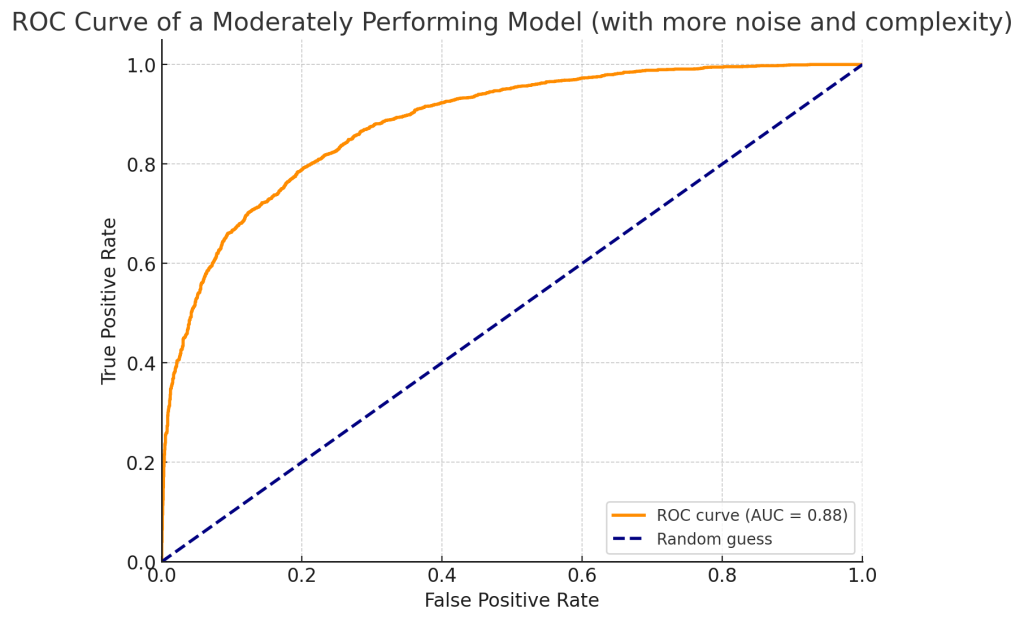
위 그래프는 성능이 적당한 모델의 ROC 곡선을 보여준다. AUC 스코어가 1에 가깝지는 않지만, 무작위 추측보다 성능이 좋은 모델이다. 곡선이 대각선보다 위에 있지만 완벽하지 않다는 점에서, 모델이 어느 정도의 예측력을 가지고 있으나 오류도 포함하고 있음을 알 수 있다. AUC 스코어는 0.7에서 0.85 사이에 위치해 성능이 보통 이상이다.
ROC 곡선의 좌측 상단에 가까울수록 모델의 성능이 좋다고 해석된다. 즉, 재현율이 높고 False Positive Rate가 낮은 경우다.
8. AUC (Area Under Curve)
AUC는 ROC 곡선 아래의 면적을 말하며, 모델의 전반적인 성능을 평가할 수 있는 단일 값이다. AUC 값은 0에서 1 사이의 값으로 나타나며, 1에 가까울수록 완벽한 분류 성능을 의미한다.
- AUC 해석:
- AUC = 1: 완벽한 분류기
- AUC = 0.5: 랜덤 분류기 (동전을 던져서 결정하는 수준)
- AUC < 0.5: 성능이 좋지 않은 모델
- 적용 예시:
- 의료 분야: 암 진단 모델의 AUC 값이 높을수록 더 정확한 진단을 기대할 수 있다.
- 금융 분야: 신용 위험 평가에서 AUC 값이 높다면 더 좋은 대출 승인 결정을 할 수 있다.